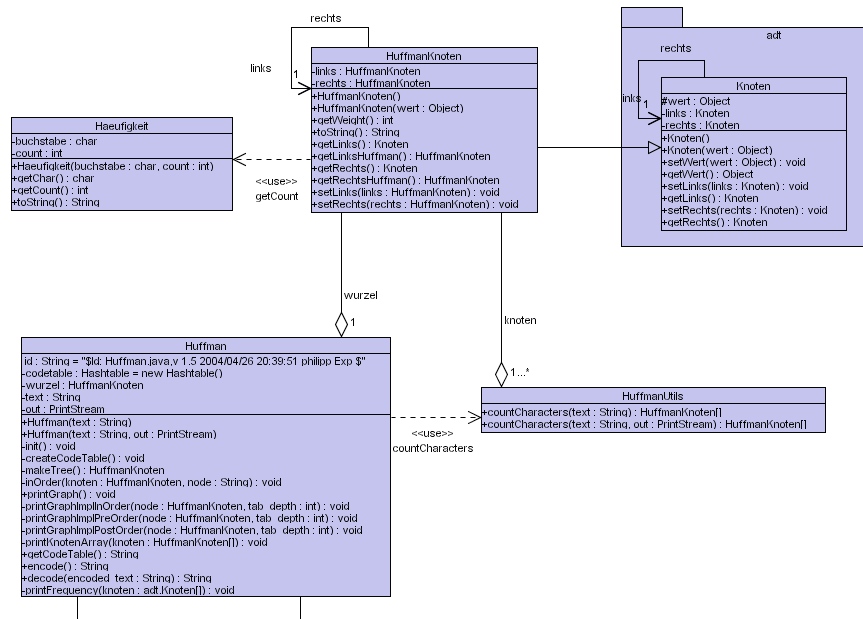
| 29.5
Klassenhierarchie des Huffman-Kodierers bzw. -Dekodierers Die in 29.5 und 29.6 dargestellte Lösung stammt von Philipp Kirchhofer (Schüler des hier dargestellten Kursuses). |
|
| Die Fachklassen | Kodierung und Dekodierung ist in der Fachklasse Huffmann implementiert. Der zur Erzeugung des Kodes wichtige Baum wird über eine Wurzel verwaltet. Deshalb aggregiert die Klasse Huffman eine HuffmanKnoten-Objekt, dessen Klasse von Knoten (das Paket adt muss also zugänglich sein) erbt. Die Klasse Häufigkeit dient dazu in den Knoten, die Häufigkeit zunächst eines Buchstabens, dann die, der in einem Teilbaum abgelegten Buchstaben zu speichern. Die Klasse HuffmanUtils schließlich dient dazu, die Häufigkeitsanalysen durchzuführen und die einzelnen Buchstaben in einer Liste von Elementarbäumen (= Wurzeln) abzulegen. Diese Liste wird in einer Reihung von Huffmanknoten abgelegt. Die genaue Spezifikation der Klassen und ihrer Methoden entnehmen man den Kommentaren in den Quelltexten (Kap. 29.6). |
|
|
|
| Die GUI-Klassen | Von den Fachklassen getrennt, listen wir noch die Klassen auf, die mit und ohne einer grafischen Oberfläche, erlauben, einen eingegeben String nach Huffman zu kodieren und zu dekodieren. Im ersten Fall handelt es sich also um eine GUI-Klasse und im zweiten Fall eine Klasse, die auf Konsolenebene die Fachklassen testet. |
|
|
|
| Da wir
ohne großen Aufwand die GUI als Applikation und als Applet laufen lassen
wollen, lagern wir die eigentliche Frameklasse aus. Die UML-Notation zeigt
das Vorgehen sehr deutlich. |
|
| zu | 29.6 QuellKodes zum Huffman-Kodierer |
| zur Startseite | www.pohlig.de (C) MPohlig 2004 |